Stichwortsuche versteht kein einziges Wort
Tippen Sie “Übersetzungsleistungen für Gerichtsverfahren” in eine klassische Suche, und sie sucht nach genau diesen Buchstabenfolgen. Steht im passenden Eintrag “Dolmetschen vor Gericht”, finden Sie nichts. Gleiche Bedeutung, andere Wörter, kein Treffer.
Das ist das Grundproblem jeder Volltextsuche. Sie matcht Zeichen, nicht Bedeutung.
Semantische Suche dreht das um. Sie findet, was gemeint ist, nicht, was getippt wurde. Und das Werkzeug dafür heißt Vektordatenbank.
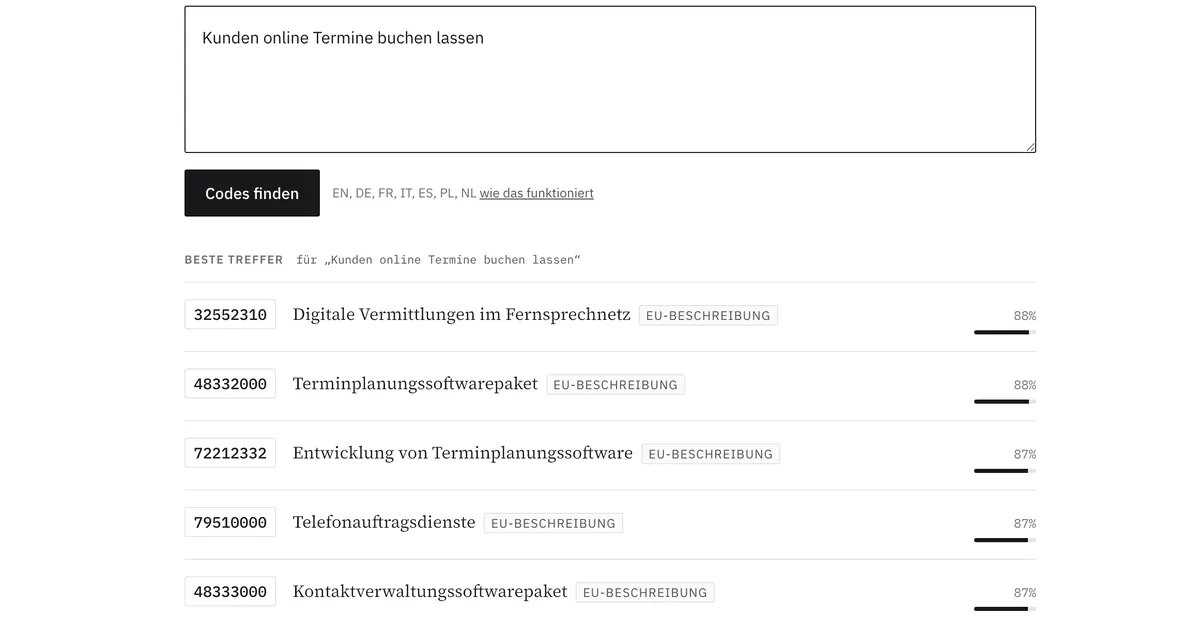
Wir haben so eine Suche für unser eigenes Produkt TenderCodes gebaut, eine Suche über die europäischen Vergabe-Klassifizierungscodes (CPV). Im Lauf dieses Posts ist TenderCodes das Arbeitsbeispiel.
Die Technik dahinter ist dieselbe, egal ob Sie Produktkataloge, Support-Tickets oder Wissensartikel durchsuchbar machen.
Was eine Vektordatenbank eigentlich ist
Ein Embedding-Modell liest einen Text und gibt eine lange Liste von Zahlen zurück. Einen Vektor. Bei dem Modell, das wir verwenden, sind das genau 1024 Zahlen pro Text.
Diese 1024 Zahlen sind keine Zufallswerte. Sie sind eine Position im Raum. Texte mit ähnlicher Bedeutung landen an benachbarten Positionen, auch wenn sie kein Wort gemeinsam haben.
“Dolmetschen vor Gericht” und “Übersetzungsleistungen für Gerichtsverfahren” liegen dicht beieinander. “Bagger mieten” liegt weit weg.
Eine Vektordatenbank ist schlicht ein Speicher, der diese Vektoren ablegt und blitzschnell die nächstgelegenen Nachbarn zu einem Suchvektor findet. Das ist der ganze Trick. Suche wird zu Geometrie.
Wie nah zwei Vektoren beieinander liegen, misst man typischerweise über die Kosinus-Ähnlichkeit: 1,0 bedeutet identische Richtung, 0 bedeutet nichts miteinander zu tun. In TenderCodes zeigen wir genau diesen Wert als Konfidenz an. 60 Prozent oder mehr gelten als starker Treffer.
Warum Postgres reicht, bis es das nicht mehr tut
Hier kommt die Entscheidung, an der die meisten Teams hängen bleiben: Pinecone? Weaviate? Qdrant? Es gibt einen ganzen Markt dedizierter Vektordatenbanken, jede mit eigener API, eigenem Betrieb, eigener Rechnung.
Wir haben keine davon genommen. Wir haben Postgres genommen.
Postgres kann seit der Erweiterung pgvector Vektoren nativ speichern und durchsuchen. In unserem Schema ist das eine einzige Zeile:
enable_extension "vector"
# ...
t.vector "embedding", limit: 1024Eine ganz normale Spalte, nur eben vom Typ Vektor mit 1024 Dimensionen. Die Dimensionszahl ist übrigens nicht frei wählbar: Sie ergibt sich aus dem Embedding-Modell.
Unser Modell liefert 1024-dimensionale Vektoren, also hat die Spalte 1024 als Limit. Nimmt man ein anderes Modell, ändert sich diese Zahl mit.
Warum diese Zurückhaltung? Weil jede zusätzliche Datenbank ein zusätzliches System ist, das jemand betreiben, sichern, überwachen und aktuell halten muss.
Ihre Daten liegen ohnehin schon in Postgres. Die Vektoren danebenzulegen heißt: ein System weniger. Ein Backup-Konzept weniger. Ein Ort, an dem ein Join zwischen Suchtreffer und Geschäftsdaten einfach funktioniert.
Wann reicht es nicht mehr? Wenn Sie zig Millionen Vektoren mit harten Latenzbudgets im einstelligen Millisekundenbereich bedienen, fängt eine spezialisierte Engine an, sich zu lohnen. Das ist eine reale Grenze, nur deutlich weiter entfernt, als die Marketingseiten der Vektordatenbank-Anbieter suggerieren.
Wir folgen hier demselben Prinzip wie bei jeder Architekturwahl: Postgres, bis es nicht mehr reicht. Wo genau diese Grenze liegt, haben wir gesondert ausgeführt unter PostgreSQL ist die einzige Datenbank, die Sie brauchen (bis sie es nicht mehr ist).
Der Index: HNSW und der ehrliche Kompromiss
Eine Million Vektoren der Reihe nach mit dem Suchvektor zu vergleichen wäre korrekt, aber langsam. Deshalb gibt es Vektor-Indizes. Wir nutzen HNSW:
t.index ["embedding"],
name: "index_cpv_official_translations_on_embedding_hnsw",
opclass: :vector_cosine_ops, using: :hnswvector_cosine_ops sagt dem Index, dass wir nach Kosinus-Ähnlichkeit suchen. using: :hnsw wählt den Indextyp.
Und hier die Ehrlichkeit, die zu jeder Vektorsuche gehört: HNSW ist ein approximativer Index. Er findet die nächsten Nachbarn fast immer, aber nicht mit hundertprozentiger Garantie.
Sie tauschen einen winzigen Verlust an Trefferqualität (Recall) gegen einen riesigen Gewinn an Geschwindigkeit. Für eine Suche, bei der ohnehin Bedeutung und nicht Pixelgenauigkeit zählt, ist das ein guter Tausch.
HNSW hat zwei Stellschrauben, die das Verhältnis von Bauzeit, Speicher, Suchgeschwindigkeit und Recall bestimmen. Drehen Sie sie zu konservativ, wird der Index langsam gebaut und groß. Drehen Sie sie zu aggressiv, sinkt der Recall.
Die Standardwerte sind für die meisten Bestände ein vernünftiger Startpunkt. Messen Sie, bevor Sie daran drehen.
Das selbst gehostete Embedding-Modell: der teure Teil
Vektoren speichern ist einfach. Vektoren erzeugen ist die Entscheidung, an der es interessant wird.
Der bequeme Weg: die Embeddings-API von OpenAI. Ein HTTP-Call, kein Modell, kein Betrieb. Für viele Projekte ist das die richtige Wahl.
Für uns nicht. TenderCodes verspricht im Produkt wörtlich:
Die semantische Suche nutzt lokal berechnete Satz-Embeddings (multilingual-e5-large). Ihre Anfrage verlässt unsere Server nicht.
Diesen Satz kann man nicht schreiben und gleichzeitig jede Suchanfrage an einen US-Anbieter schicken. Wer Datenschutz als Versprechen verkauft, muss ihn in der Architektur einlösen.
Also hosten wir das Modell selbst. Die Anfrage wird auf unseren Servern in einen Vektor umgerechnet und geht nirgendwo sonst hin. Warum das für EU-Kunden zählt und wo die Grenzen liegen, haben wir im Detail beschrieben unter KI ohne Cloud: On-Premise-Datenschutz in Europa.
Das hat einen Preis, und der Preis ist Betrieb. Das Modell läuft als eigener Dienst neben der Rails-Anwendung, ein kleiner FastAPI-Service mit uvicorn.
Den müssen wir paketieren, deployen, überwachen und bei Updates pflegen. Ein OpenAI-Call hätte nichts davon gebraucht.
Konkret heißt selbst gehostet: ein Docker-Image, in das das Modell zur Build-Zeit eingebacken wird, damit es zur Laufzeit nie ins Netz greift. Im laufenden Container stehen die Umgebungsvariablen HF_HUB_OFFLINE=1 und TRANSFORMERS_OFFLINE=1. Offline ist hier kein Zufall, sondern Teil des Versprechens.
Ein Modell auf der CPU, das nicht umkippt
Ein Detail, das man leicht unterschätzt: Embedding-Modelle wollen eigentlich eine GPU. Wir lassen unseres auf der CPU laufen.
Damit das praktikabel ist, exportieren wir das Modell beim Build nach ONNX und quantisieren es auf int8 mit einem arm64-Preset. Aus großen Fließkommazahlen werden kleine Ganzzahlen.
Das Modell wird kleiner und auf der CPU deutlich schneller, bei minimalem Qualitätsverlust. Eine GPU-Rechnung pro Monat spart das ganz nebenbei.
Der zweite Trick ist Bescheidenheit unter Last. Ein CPU-Embedding-Dienst, der zehn Anfragen gleichzeitig annimmt, bringt sich selbst zum Stillstand. Also lassen wir bewusst nur eine Berechnung zur Zeit zu:
_limiter = anyio.CapacityLimiter(1) # one encode at a time, everDazu startet der Dienst mit --workers 1. Single-Flight nennt sich dieses Muster: lieber Anfragen kurz anstellen lassen, als unter Überlast komplett wegbrechen.
Ein /readyz-Endpunkt meldet zudem, wann das Modell geladen und der Dienst gesund ist, damit das Deployment nicht zu früh Traffic schickt.
Ist das eleganter als ein OpenAI-Call? Nein. Ist es notwendig, wenn die Anfrage den Server nicht verlassen darf? Ja. Genau das ist der Tausch.
Warum ein mehrsprachiges Modell
CPV-Codes beschreiben dieselbe Sache in vielen EU-Sprachen. Eine Vergabestelle in Warschau sucht polnisch, eine in Lissabon portugiesisch, eine in München deutsch. Eine Suche, die nur eine Sprache versteht, wäre für einen europäischen Markt nutzlos.
Deshalb fiel die Wahl auf ein mehrsprachiges Modell: multilingual-e5-large-instruct (die Produkt-Copy oben kürzt es zum Familiennamen multilingual-e5-large ab, gemeint ist dasselbe Modell). “Multilingual” ist hier das entscheidende Wort: dasselbe Modell bedient alle sieben Sprachen, ohne dass für jede ein eigenes trainiert werden müsste.
Beschreiben Sie eine Leistung auf Deutsch, sucht das Modell sauber über die deutschen CPV-Beschreibungen; auf Polnisch sucht es über die polnischen. So funktioniert dieselbe semantische Suche in jeder der sieben unterstützten Sprachen gleich gut, über alle 9.454 CPV-Codes.
Ein Detail aus der e5-Familie, das in der Praxis zählt: Anfrage und Inhalt werden nicht gleich behandelt. Die Suchanfrage bekommt eine kurze Instruktionszeile vorangestellt, die zu durchsuchenden Texte nicht. Das Modell wurde so trainiert.
Hält man sich nicht daran, sinkt die Trefferqualität spürbar. Solche Eigenheiten muss man kennen, sonst sucht man stundenlang nach einem Bug, der keiner ist.
Wie eine Anfrage tatsächlich durchläuft
Genug Theorie. So sieht eine Suche von Eingabe bis Treffer aus.
Zuerst wird der Suchtext zum Vektor. Diese Umrechnung ist der teure Teil, also wird das Ergebnis eine Stunde lang zwischengespeichert. Dieselbe Anfrage zweimal zu stellen kostet beim zweiten Mal nichts:
vec = Rails.cache.fetch("embed:query:#{Digest::SHA256.hexdigest(query)}", expires_in: 1.hour) do
Embedding::Client.embed(text: query, mode: "query")
endDann sucht Postgres die nächsten Nachbarn. Der Operator <=> ist die Kosinus-Distanz; 1 - Distanz ergibt die Ähnlichkeit. Postgres sortiert die 50 nächsten Kandidaten und behält nur die, deren Ähnlichkeit über dem Schwellwert liegt (standardmäßig 0,6).
Kein Treffer über der Schwelle, kein Treffer. Lieber ehrlich leer als irreführend voll.
Und wenn der Embedding-Dienst gerade nicht erreichbar ist? Dann fällt die Suche nicht aus, sondern zurück, auf eine schlichte Stichwortsuche mit ILIKE:
rescue Embedding::ClientError
fallback_keyword(query: query, locale: locale, limit: limit)Stichwortsuche ist schlechter als semantische Suche. Aber sie ist unendlich besser als eine Fehlermeldung. Der Nutzer sieht in dem Fall einen Hinweis, dass gerade Stichworttreffer angezeigt werden. Degradieren statt abstürzen.
Genau hier zahlt sich aus, dass die Vektoren in Postgres neben den Geschäftsdaten liegen: Der Fallback ist nur ein anderes WHERE auf derselben Tabelle, kein zweites System, das auch noch erreichbar sein muss.
Was Sie daraus mitnehmen, auch ohne TenderCodes
Sie müssen nie eine Ausschreibung anfassen, um aus diesem Aufbau etwas mitzunehmen.
Wenn Sie semantische Suche brauchen, fangen Sie nicht mit der Suche nach der perfekten Vektordatenbank an. Fangen Sie mit der Datenbank an, die Sie schon haben. Steht sie auf Postgres, ist pgvector wahrscheinlich genug, länger als Sie denken.
Derselbe Baukasten trägt weiter, als Sie zunächst vermuten. Eine durchsuchbare Wissensbasis im Unternehmen ist im Kern dieselbe Mechanik, wie wir sie unter Enterprise-Suche und KI-Wissensdatenbanken ausführen.
Die schwierige Entscheidung ist nicht der Speicher. Sie ist, wer die Vektoren erzeugt. Eine externe API ist schneller startklar, ein selbst gehostetes Modell ist mehr Betrieb, aber die einzige Antwort, wenn Anfragen den Server nicht verlassen dürfen.
Beide Wege sind legitim. Wählen Sie bewusst, nicht aus Bequemlichkeit.
Und seien Sie ehrlich zu den Kompromissen. HNSW ist approximativ, Quantisierung kostet ein Quäntchen Qualität, ein CPU-Dienst muss sich unter Last bescheiden.
Nichts davon ist ein Makel. Es sind die normalen Abwägungen einer Technik, die ihre Versprechen halten soll, statt nur gut zu klingen.
Überlegen Sie, ob semantische Suche oder eine selbst gehostete KI-Komponente zu Ihrem Produkt passt? Lassen Sie uns gemeinsam draufschauen. Ehrlich, ohne Buzzwords, mit Blick auf Betrieb und Datenschutz.